Learning features to compare distributions Arthur Gretton Gatsby Computational Neuroscience Unit, University College London
NIPS 2016 Workshop on Adversarial Learning, Barcelona Spain
1/28
Goal of this talk Have: Two collections of samples X Y from unknown distributions P and Q. Goal: Learn distinguishing features that indicate how P and Q differ.
2/28
Goal of this talk Have: Two collections of samples X Y from unknown distributions P and Q. Goal: Learn distinguishing features that indicate how P and Q differ.
2/28
Divergences
3/28
Divergences
4/28
Divergences
5/28
Divergences
6/28
Divergences
Sriperumbudur, Fukumizu, G, Schoelkopf, Lanckriet (2012) 7/28
Overview The Maximum mean discrepancy: How to compute and interpret the MMD How to train the MMD Application to troubleshooting GANs
The ME test statistic: Informative, linear time features for comparing distributions How to learn these features
TL;DR: Variance matters. 8/28
The maximum mean discrepancy Are P and Q different?
P(x) Q(y)
−6
−4
−2
0
2
4
6
9/28
Maximum mean discrepancy (on sample)
10/28
Maximum mean discrepancy (on sample)
Observe X
x1
xn
P Observe Y
y1
yn
Q
10/28
Maximum mean discrepancy (on sample) Gaussian kernel on xi Gaussian kernel on yi
10/28
Maximum mean discrepancy (on sample) P
v : mean embedding of P
Q
v : mean embedding of Q
v P
v
1 m
m i 1
k xi v 10/28
Maximum mean discrepancy (on sample) P
v : mean embedding of P
Q
v : mean embedding of Q
v witness v
P
v
Q
v
10/28
Maximum mean discrepancy (on sample)
MMD
2
witness v 1 n n 1
2
k xi xj
i j
2 n2
1 n n
1
k yi yj i j
k xi yj i j
11/28
Overview Dogs P and fish Q example revisited Each entry is one of k dogi dogj , k dogi fishj , or k fishi fishj
12/28
Overview The maximum mean discrepancy: MMD
1
2
n n
1
k dogi dogj i j
2 n2
1 n n
1
k fishi fishj i j
k dogi fishj i j
13/28
Asymptotics of MMD The MMD: MMD
1
2
n n
1
k xi xj i j
2 n2
1 n n
1
k yi yj i j
k x i yj i j
but how to choose the kernel?
14/28
Asymptotics of MMD The MMD: MMD
1
2
n n
1
k xi xj i j
2 n2
1 n n
1
k yi yj i j
k x i yj i j
but how to choose the kernel?
Perspective from statistical hypothesis testing: 2
When P
Q then MMD “close to zero”.
When P
Q then MMD “far from zero”
2
2
Threshold c for MMD gives false positive rate 14/28
A statistical test MMD density 0.7
P=Q P≠ Q
d n ⇥ MMD
2
0.6
0.5
Prob. of
0.4
cα = 1−α quantile when P=Q
0.3
0.2
False negatives 0.1
0 −2
−1
0
1
2
3
4
5
6
2
d n ⇥ MMD
15/28
A statistical test MMD density 0.7
P=Q P≠ Q
d n ⇥ MMD
2
0.6
0.5
Prob. of
0.4
cα = 1−α quantile when P=Q
0.3
0.2
False negatives 0.1
0 −2
−1
0
1
2
3
4
5
6
2
d n ⇥ MMD
Best kernel gives lowest false negative rate (=highest power) 15/28
A statistical test MMD density 0.7
P=Q P≠ Q
d n ⇥ MMD
2
0.6
0.5
Prob. of
0.4
cα = 1−α quantile when P=Q
0.3
0.2
False negatives 0.1
0 −2
−1
0
1
2
3
4
5
6
2
d n ⇥ MMD
Best kernel gives lowest false negative rate (=highest power) .... but can you train for this?
15/28
Asymptotics of MMD When P
Q, statistic is asymptotically normal, MMD
2
MMD P Q Vn P Q
D
0 1
where MMD P Q is population MMD, and Vn P Q
O n
1
.
MMD distribution and Gaussian fit under H1 14
Prob. density
12
Empirical PDF Gaussian fit
10 8 6 4 2 0 0
0.05
0.1
0.15
0.2
MMD
0.25
0.3
0.35
0.4 16/28
Asymptotics of MMD Where P
Q, statistic has asymptotic distribution nMMD
2 l l 1
zl2
2 where
MMD density under H0 0.7
χ2 sum Empirical PDF
0.6
i
i
x
k x x
i
x dP x
centred
Prob. density
0.5
zl
0.4
0 2
iid
0.3
0.2
0.1
0 −2
−1
0
1
2
3
4
5
6
n× MMD2 17/28
Optimizing test power The power of our test (Pr1 denotes probability under P
Pr1 nMMD
2
Q):
c
18/28
Optimizing test power The power of our test (Pr1 denotes probability under P
Pr1 nMMD 1
2
c c
n
Q):
Vn P Q
MMD2 P Q Vn P Q
where is the CDF of the standard normal distribution. c is an estimate of c test threshold.
18/28
Optimizing test power The power of our test (Pr1 denotes probability under P
Pr1 nMMD 1
2
c c
n
Q):
Vn P Q O n
3 2
MMD2 P Q Vn P Q O n
1 2
First term asymptotically negligible!
18/28
Optimizing test power The power of our test (Pr1 denotes probability under P
Pr1 nMMD 1
2
c c
n
Q):
Vn P Q
MMD2 P Q Vn P Q
To maximize test power, maximize MMD2 P Q Vn P Q (Sutherland, Tung, Strathmann, De, Ramdas, Smola, G., in review for ICLR 2017)
Code: github.com/dougalsutherland/opt-mmd 18/28
Troubleshooting for generative adversarial networks
MNIST samples
Samples from a GAN
19/28
Troubleshooting for generative adversarial networks
MNIST samples
Samples from a GAN Power for optimzed ARD kernel: 1.00 at 0 01
ARD map
Power for optimized RBF kernel: 0.57 at 0 01
19/28
Benchmarking generative adversarial networks
20/28
The ME statistic and test
21/28
Distinguishing Feature(s) P
v : mean embedding of P
Q
v : mean embedding of Q
v witness v
P
v
Q
v
22/28
Distinguishing Feature(s) witness2 v
Take square of witness (only worry about amplitude) 23/28
Distinguishing Feature(s)
New test statistic: witness2 at a single v ; Linear time in number n of samples ....but how to choose best feature v ?
23/28
Distinguishing Feature(s)
v
Best feature = v that maximizes witness2 v
?? 23/28
Distinguishing Feature(s) witness2 v
Sample size n
3
24/28
Distinguishing Feature(s)
Sample size n
50
24/28
Distinguishing Feature(s)
Sample size n
500
24/28
Distinguishing Feature(s)
Pwx) Qwy) wittess 2 wv)
Population witness2 function
24/28
Distinguishing Feature(s)
Pwx) Qwy) wittess 2 wv)
v?
v?
24/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
25/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
25/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
Pwx) Qwy) wittess 2 wv)
25/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
wittess 2 wv) vsristce X wv)
25/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
wittess 2 wv) vsristce Y wv)
25/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
wittess 2 wv) vsristce of v
25/28
Variance of witness function Variance at v = variance of X at v + variance of Y at v. witness2 v ME Statistic: n v n variance of v .
λˆn (v)
v∗
Best location is v that maximizes n . Improve performance using multiple locations vj
J j 1
25/28
Distinguishing Positive/Negative Emotions
happy
neutral
surprised
35 females and 35 males (Lundqvist et al., 1998). 48 34 1632 dimensions. Pixel features. Sample size: 402.
afraid
angry
disgusted
The proposed test achieves maximum test power in time O n . Informative features: differences at the nose, and smile lines. 26/28
Distinguishing Positive/Negative Emotions 5andRP feature
neutral
surprised
1.0
PRwer ⟶
happy
0.5 0.0
afraid
angry
+ vs. -
disgusted
The proposed test achieves maximum test power in time O n . Informative features: differences at the nose, and smile lines. 26/28
Distinguishing Positive/Negative Emotions 5andRP feature PrRpRsed
neutral
surprised
1.0
PRwer ⟶
happy
0.5 0.0
afraid
angry
+ vs. -
disgusted
The proposed test achieves maximum test power in time O n . Informative features: differences at the nose, and smile lines. 26/28
Distinguishing Positive/Negative Emotions 5DndRP feDture PrRpRsed 00D (quDdrDtic tiPe)
neutral
surprised
1.0
PRwer ⟶
happy
0.5 0.0
afraid
angry
+ vs. -
disgusted
The proposed test achieves maximum test power in time O n . Informative features: differences at the nose, and smile lines. 26/28
Distinguishing Positive/Negative Emotions
happy
neutral
surprised
afraid
angry
disgusted
Learned feature The proposed test achieves maximum test power in time O n . Informative features: differences at the nose, and smile lines.
26/28
Distinguishing Positive/Negative Emotions
happy
neutral
surprised
afraid
angry
disgusted
Learned feature The proposed test achieves maximum test power in time O n . Informative features: differences at the nose, and smile lines. Code: https://github.com/wittawatj/interpretable-test
26/28
Final thoughts Witness function approaches: Diversity of samples: MMD test uses pairwise similarities between all samples ME test uses similarities to J reference features
Disjoint support of generator/data distributions Witness function is smooth
Other discriminator heuristics: Diversity of samples by minibatch heuristic (add as feature distances to neighbour samples) Salimans et al. (2016) Disjoint support treated by adding noise to “blur” images Arjovsky and Bottou (2016), Huszar (2016)
27/28
Co-authors Students and postdocs: Kacper Chwialkowski (at Voleon) Wittawat Jitkrittum Heiko Strathmann Dougal Sutherland
Collaborators
Questions?
Kenji Fukumizu Krikamol Muandet Bernhard Schoelkopf Bharath Sriperumbudur Zoltan Szabo 28/28
Testing against a probabilistic model
29/28
Statistical model criticism MMD P Q
f
2
sup
f
1
EQ f
Ep f
0.4 0.3 0.2
p(x)
0.1 -4
q(x) 2
-2
4
-0.1
f *(x)
-0.2 -0.3
f
x is the witness function
Can we compute MMD with samples from Q and a model P ? Problem: usualy can’t compute Ep f in closed form. 30/28
Stein idea To get rid of Ep f in sup Eq f
Ep f
1
f
we define the Stein operator Tp f
xf
f
x
log p
Then EP T P f
0
subject to appropriate boundary conditions.
(Oates, Girolami, Chopin, 2016)
31/28
Maximum Stein Discrepancy Stein operator
Tp f
xf
f
x
log p
Maximum Stein Discrepancy (MSD) MSD p q
sup Eq Tp g
g
1
Ep Tp g
32/28
Maximum Stein Discrepancy Stein operator
Tp f
xf
f
x
log p
Maximum Stein Discrepancy (MSD) MSD p q
sup Eq Tp g
g
1
⇠ Ep⇠ T⇠ pg ⇠
32/28
Maximum Stein Discrepancy Stein operator
Tp f
xf
f
x
log p
Maximum Stein Discrepancy (MSD) MSD p q
sup Eq Tp g
g
1
⇠ Ep⇠ T⇠ pg ⇠
sup Eq Tp g
g
1
32/28
Maximum Stein Discrepancy Stein operator Tp f
xf
f
x
log p
Maximum Stein Discrepancy (MSD) sup Eq Tp g
MSD p q
g
1
⇠ Ep⇠ T⇠ pg ⇠
sup Eq Tp g
g
1
0.4 0.2 -4
2
-2 -0.2 -0.4
4
p(x) q(x) g *(x)
-0.6 32/28
Maximum Stein Discrepancy Stein operator Tp f
xf
f
x
log p
Maximum Stein Discrepancy (MSD) sup Eq Tp g
MSD p q
g
1
⇠ Ep⇠ T⇠ pg ⇠
sup Eq Tp g
g
1
0.4 0.3
p(x)
0.2
q(x) g *(x)
0.1
-4
-2
2
4 32/28
Maximum stein discrepancy Closed-form expression for MSD: given Z Z Strathmann, G., 2016) (Liu, Lee, Jordan 2016)
MSD p q
q, then
(Chwialkowski,
Eq hp Z Z
where hp x y
x
log p x
x
log p y k x y
y
log p y
xk
x y
x
log p x
yk
x y
x yk
x y
and k is RKHS kernel for
Only depends on kernel and x log p x . Do not need to normalize p, or sample from it. 33/28
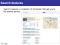
Statistical model criticism Solar activity (normalised)
3 2 1 0 1 2 1600
1700
1800
1900
2000
Year
Test the hypothesis that a Gaussian process model, learned from data , is a good fit for the test data (example from Lloyd and Ghahramani, 2015)
Code: https://github.com/karlnapf/kernel_goodness_of_fit 34/28
Statistical model criticism 0.030 Vn test Bootstrapped Bn
Frequency
0.025 0.020 0.015 0.010 0.005 0.000 0
50
100
150 Vn
200
250
300
Test the hypothesis that a Gaussian process model, learned from data , is a good fit for the test data 35/28